May 28, 2026
Evals
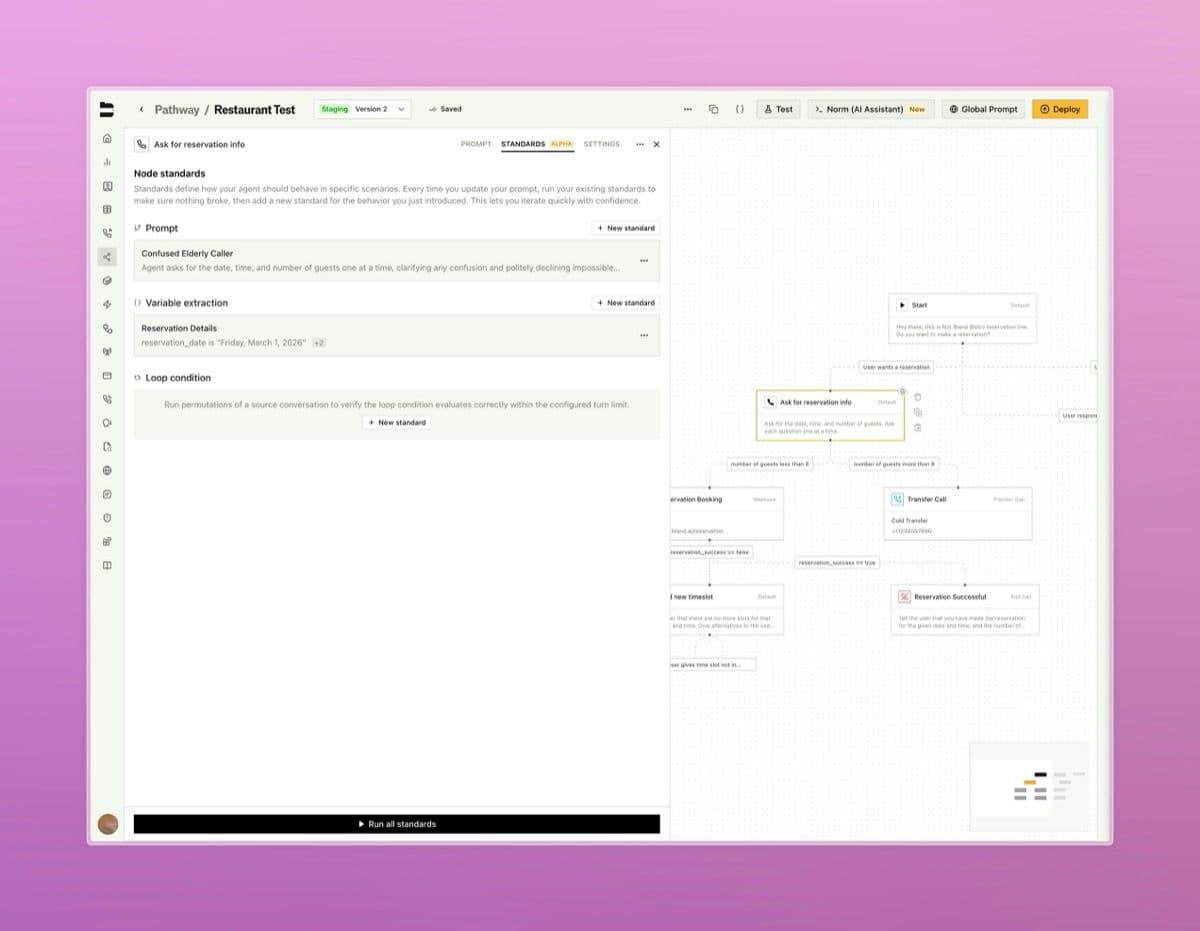
Evals run LLM judges against your call history to grade quality dimensions like audio, tone, hallucinations, and resolution. Available at the Evals page, see the docs.
- Build a workbench of eval agents, each one grading a single dimension with a custom rubric and configurable evidence sources (transcript, metadata, pathway logs, citations, tool logs, and more)
- Pick Transcript or Audio mode per agent depending on whether you need an LLM to read the transcript or a non-LLM pipeline to listen to the recording
![Analytics Dashboards Overhaul [Enterprise] — screenshot 1](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2Ftmmoa80b%2Fproduction%2F3735f21dae1cc287dc7659aa7593ea41f05c0816-1200x822.jpg&w=3840&q=75)
![SIP Wizard [Enterprise] screenshot 1](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2Ftmmoa80b%2Fproduction%2F20d9db79dfbc224df3d1cb6cdbc260fe286898b9-1200x814.jpg&w=3840&q=75)
![Outcomes [Enterprise] screenshot 1](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2Ftmmoa80b%2Fproduction%2F43a412ebdcacead6637285d6917bd47be09a30af-1200x820.jpg&w=3840&q=75)